Moe learning notes
前置知识
激活函数
使用激活函数能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,使深层神经网络表达能力更加强大,这样神经网络就可以应用到众多的非线性模型中。
Normalization
就是把输入数据X,在输送给神经元之前先对其进行平移和伸缩变换,将X的分布规范化成在固定区间范围的标准分布。
Normalization 的作用很明显,把数据拉回标准正态分布,因为神经网络的Block大部分都是矩阵运算,一个向量经过矩阵运算后值会越来越大,为了网络的稳定性,我们需要及时把值拉回正态分布。
BN vs LN
BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。
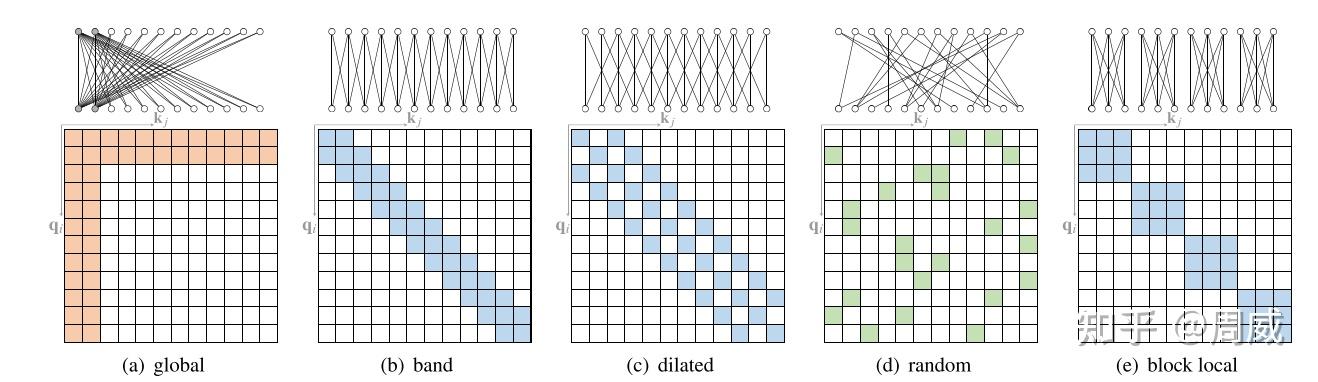
Sparse Attention
稀疏注意力机制的核心思想是在自注意力计算中引入稀疏性,即不是让序列中的每个位置都与其他所有位置进行注意力计算,而是仅选择部分位置进行计算。这种选择可以基于不同的策略,例如固定的模式(如局部窗口)、基于内容的选择(如与当前位置最相关的其他位置),或者是通过学习得到的模式。通过这种方式,稀疏注意力机制减少了计算量和内存占用,使得模型能够更高效地处理长序列。
稀疏注意力的分类
- 基于位置的稀疏注意力(position-based sparse attention):这种方法是根据位置信息来确定哪些位置之间的注意力权重是稀疏的。在基于位置的稀疏注意力中,可能会使用一些规则或启发式方法来确定哪些位置之间的交互是重要的,而其他位置之间的交互可以被忽略或减少。这种方法通常依赖于位置之间的相对距离或其他位置特征来确定稀疏连接。
- 基于内容的稀疏注意力(content-based sparse attention):这种方法是根据输入内容的特征来确定哪些位置之间的注意力权重是稀疏的。在基于内容的稀疏注意力中,可能会根据输入数据的特征向量来动态地确定哪些位置之间的交互是重要的,从而实现稀疏连接。这种方法通常会根据输入数据的内容特征来自适应地调整注意力权重,以实现更高效的计算和更好的性能。
基于位置的稀疏注意力
知识蒸馏KD
知识蒸馏就是把一个大的教师模型的知识萃取出来,把他浓缩到一个小的学生模型

离线蒸馏
离线蒸馏方式即为传统的知识蒸馏,如上图(a)。用户需要在已知数据集上面提前训练好一个teacher模型,然后在对student模型进行训练的时候,利用所获取的teacher模型进行监督训练来达到蒸馏的目的,而且这个teacher的训练精度要比student模型精度要高,差值越大,蒸馏效果也就越明显。一般来讲,teacher的模型参数在蒸馏训练的过程中保持不变,达到训练student模型的目的。蒸馏的损失函数distillation loss计算teacher和student之前输出预测值的差别,和student的loss加在一起作为整个训练loss,来进行梯度更新,最终得到一个更高性能和精度的student模型。
半监督蒸馏
半监督方式的蒸馏利用了teacher模型的预测信息作为标签,来对student网络进行监督学习,如上图(b)。那么不同于传统离线蒸馏的方式,在对student模型训练之前,先输入部分的未标记的数据,利用teacher网络输出标签作为监督信息再输入到student网络中,来完成蒸馏过程,这样就可以使用更少标注量的数据集,达到提升模型精度的目的。
自监督蒸馏
自监督蒸馏相比于传统的离线蒸馏的方式是不需要提前训练一个teacher网络模型,而是student网络本身的训练完成一个蒸馏过程,如上图(c)。具体实现方式 有多种,例如先开始训练student模型,在整个训练过程的最后几个epoch的时候,利用前面训练的student作为监督模型,在剩下的epoch中,对模型进行蒸馏。这样做的好处是不需要提前训练好teacher模型,就可以变训练边蒸馏,节省整个蒸馏过程的训练时间。
Speculative Decoding
动机
大型语言模型(LLM)的推理通常需要使用自回归采样。它们的推理过程相当缓慢,需要逐个token地进行串行解码。因此,大型模型的推理过程往往受制于访存速度,生成每个标记都需要将所有参数从存储单元传输到计算单元,因此内存访问带宽成为严重的瓶颈。
投机采样是一种可以从根本上解码计算访存比的方法,保证和使用原始模型的采样分布完全相同。它使用两个模型:一个是原始目标模型,另一个是比原始模型小得多的近似模型。近似模型用于进行自回归串行采样,而大型模型则用于评估采样结果。解码过程中,某些token的解码相对容易,某些token的解码则很困难。因此,简单的token生成可以交给小型模型处理,而困难的token则交给大型模型处理。这里的小型模型可以采用与原始模型相同的结构,但参数更少,或者干脆使用n-gram模型。小型模型不仅计算量较小,更重要的是减少了内存访问的需求。
过程
投机采样过程如下:
- 用小模型Mq做自回归采样连续生成 γ 个tokens。
- 把生成的γ个tokens和前缀拼接一起送进大模Mp执行一次forwards。(并行计算)
- 使用大、小模型logits结果做比对,如果发现某个token小模型生成的不好,重新采样这个token。重复步骤1。
- 如果小模型生成结果都满意,则用大模型采样下一个token。重复步骤1。
第2步,将γ个tokens和前缀拼成一起作为大模型输入,和自回归相比,尽管计算量一样,但是γ个tokens可以同时参与计算,计算访存比显著提升。
模型
llama1
Pre-normalization
为了提高训练的稳定性,对每个transformer层的输入进行归一化,而不是输出进行归一化。
使用RMS norm归一化函数,公式如下:

RMS Norm 的作者认为这种模式在简化了Layer Norm 的计算(平移并不会影响分布,所以去除平移),可以在减少约 7%∼64% 的计算时间
Silu激活函数

旋转编码
外推性:RoPE的旋转编码方式没有明确的最大长度限制,因此可以在推理阶段支持更长的输入文本。相比之下,传统的正弦位置编码通常需要在训练时设置最大长度,超出这一长度的输入就可能无法编码。

llama2
用来GQA和mistral的相同
mistral
该模型采用了分组查询注意力(GQA),GQA显著加快了推理速度,还减少了解码期间的内存需求,允许更高的批处理大小,从而提高吞吐量
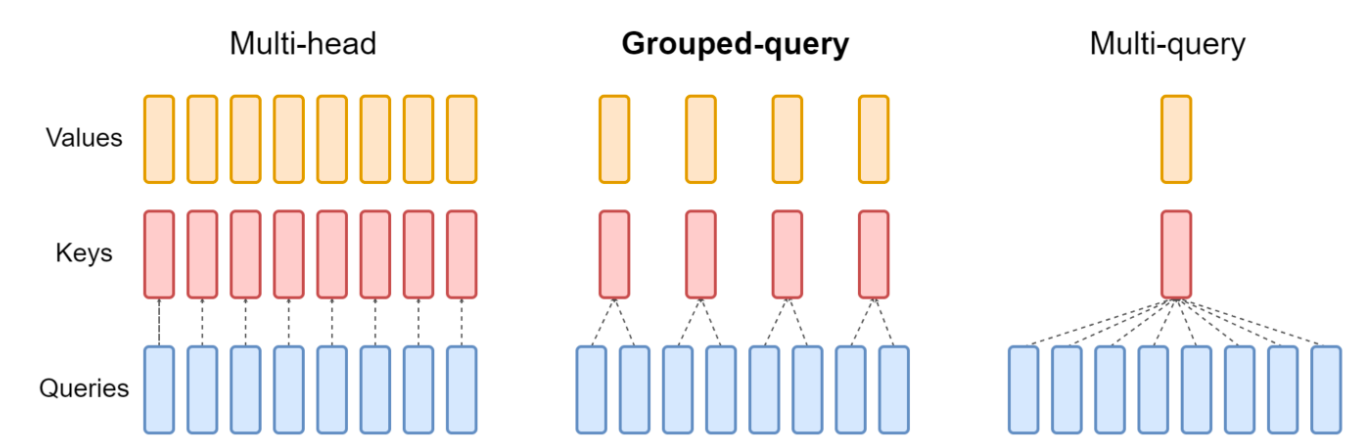
- MHA:kv缓存高
- MQA:只使用一个键值头,虽大大加快了解码器推断的速度,但MQA可能导致质量下降
- MQA:它通过折中(多于一个且少于查询头的数量,比如4个)键值头的数量,使得经过强化训练的GQA以与MQA相当的速度达到接近多头注意力的质量,即速度快 质量高
滑动窗口注意力:原始attention的操作次数与序列长度成平方关系。于是采用滑动窗口注意力,每个token只计算它前面的window size个token。如下图所示
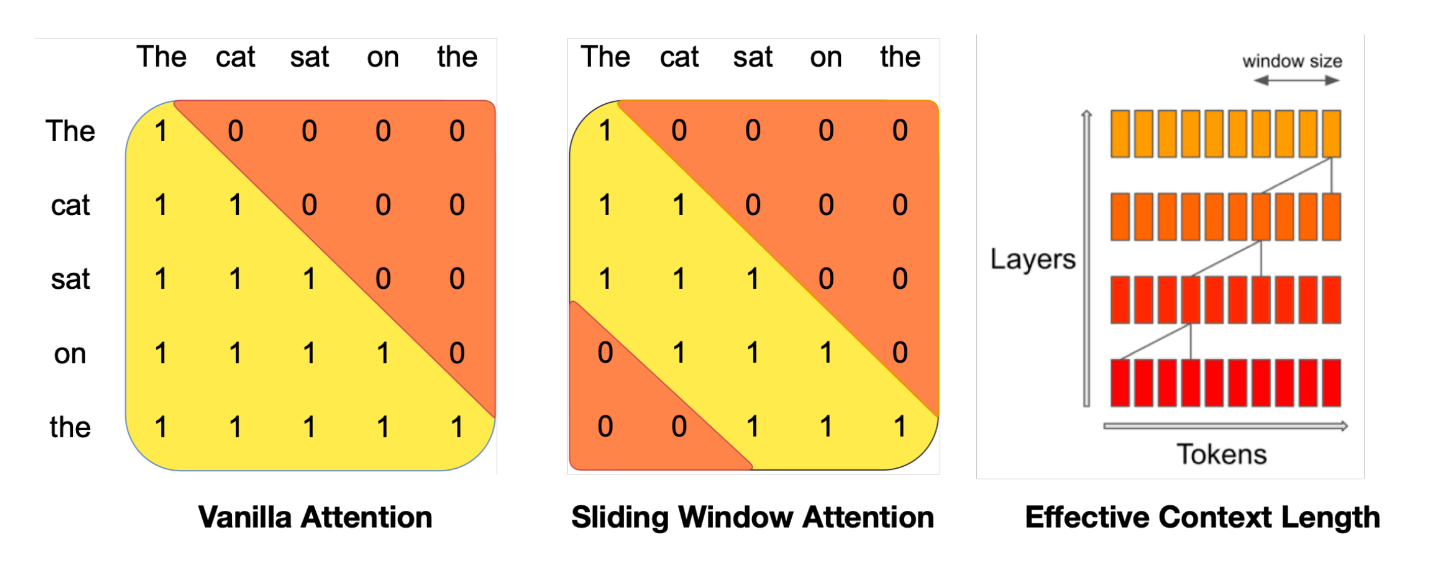
- 每个token最多可以关注来自上一层的W个token(上图中,W = 3)。请注意,滑动窗口之外的token仍然影响下一个单词预测
- 在每个注意力层,信息可以向前移动W个token。因此,在k层注意力之后,信息最多可以向前移动k个×W个token(所以滑动窗口外的token仍然有影响)
滚动缓冲区:适配于滑动窗口注意力
- 缓存的大小是固定的W,时间步长i的键和值存储在缓存的位置i mod W中。因此,当位置i大于W时,缓存中过去的值就会被覆盖,缓存的大小就会停止增加。
预填充与分块:利用prompt提前缓存k,v
- 如果prompt非常大,可以把它分成更小的块,用每个块预填充缓存。为此,可以选择窗口大小作为分块大小。因此,对于每个块,需要计算缓存和块上的注意力
mixtral 8x7B
decoder only的moe模型
每层结构如下:
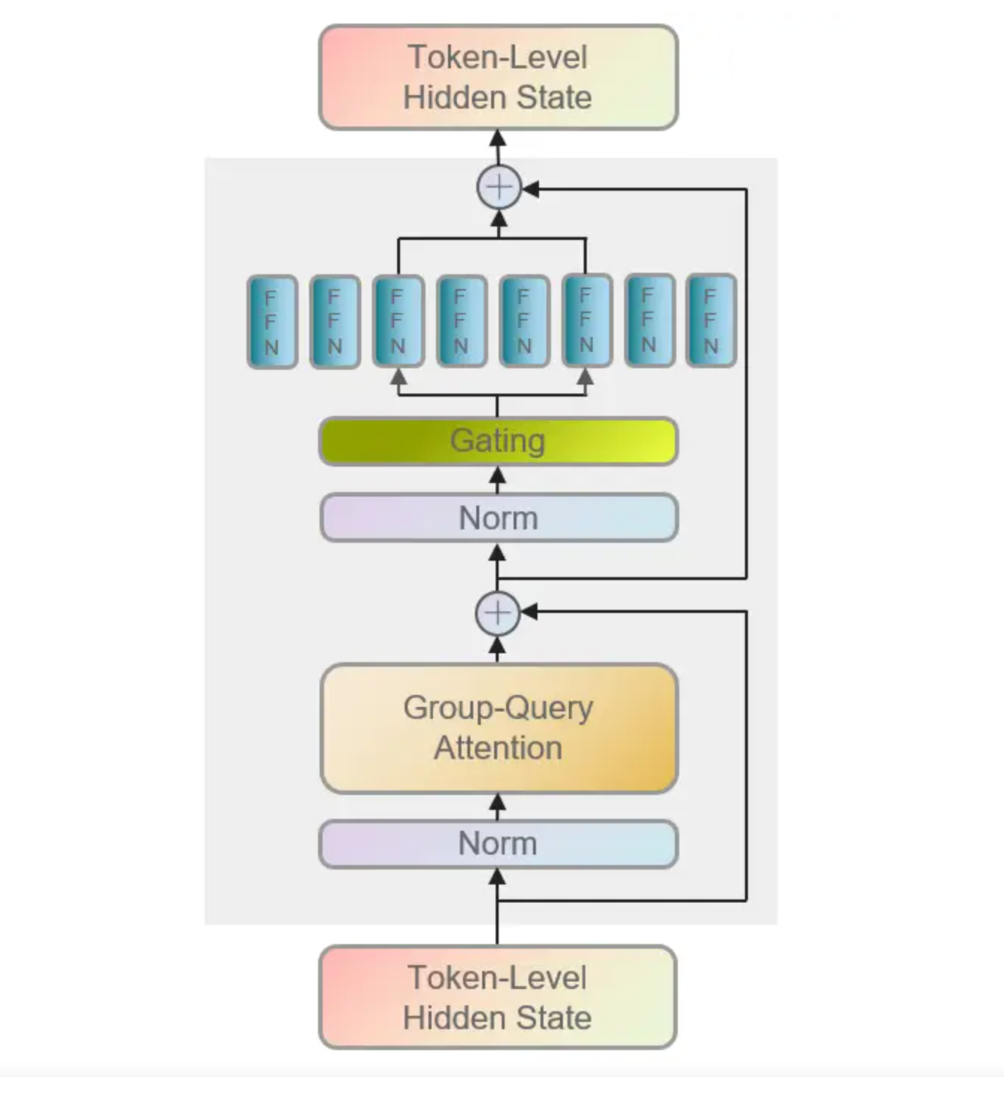
论文
SIDA
介绍
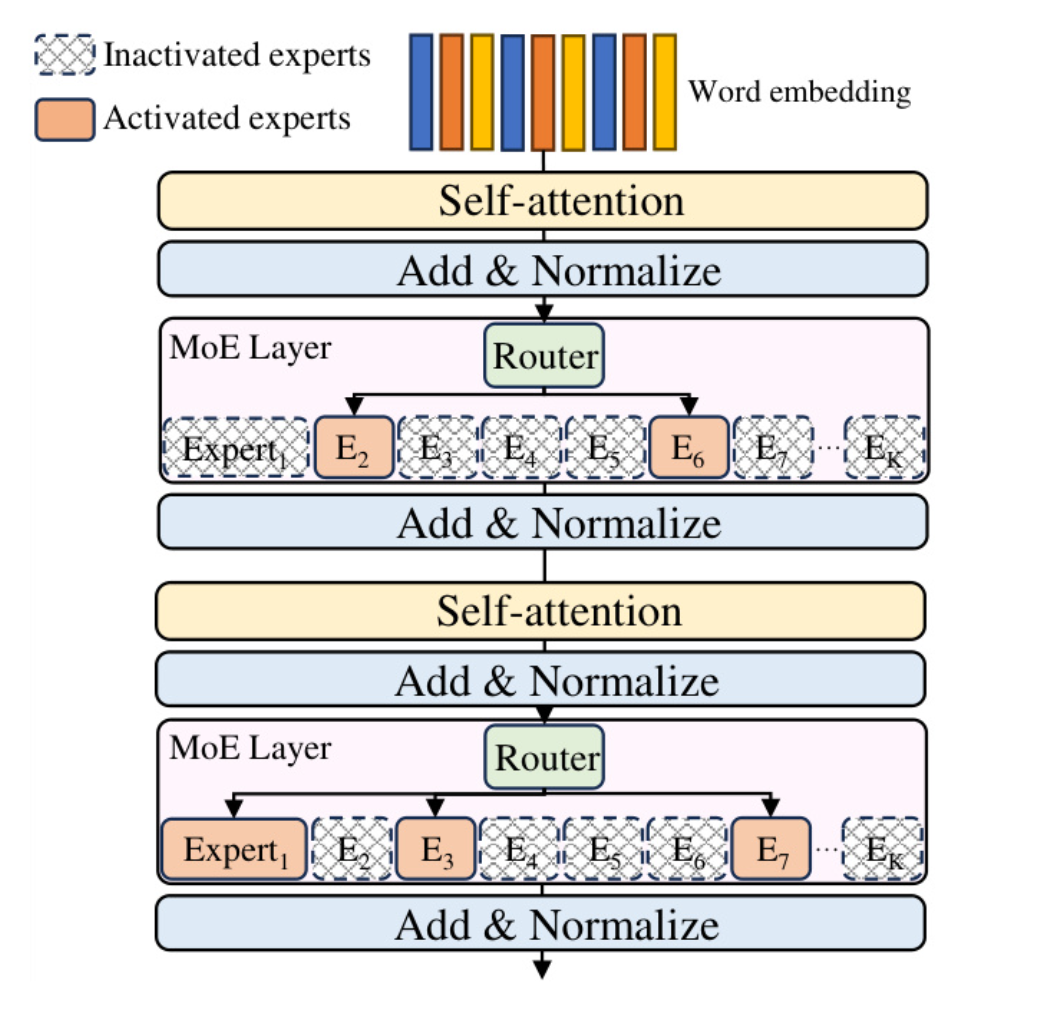
如下图transformer中的moe架构,在推理中每个moe layer只有一小部分专家被激活。但是却占用了大量的gpu memory
data-awareness:根据传入数据来确定技术或策略的设计
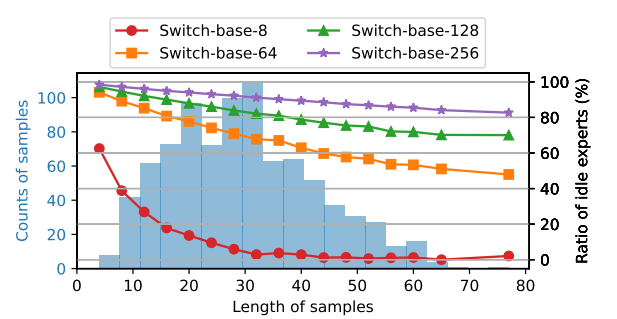
背景和动机
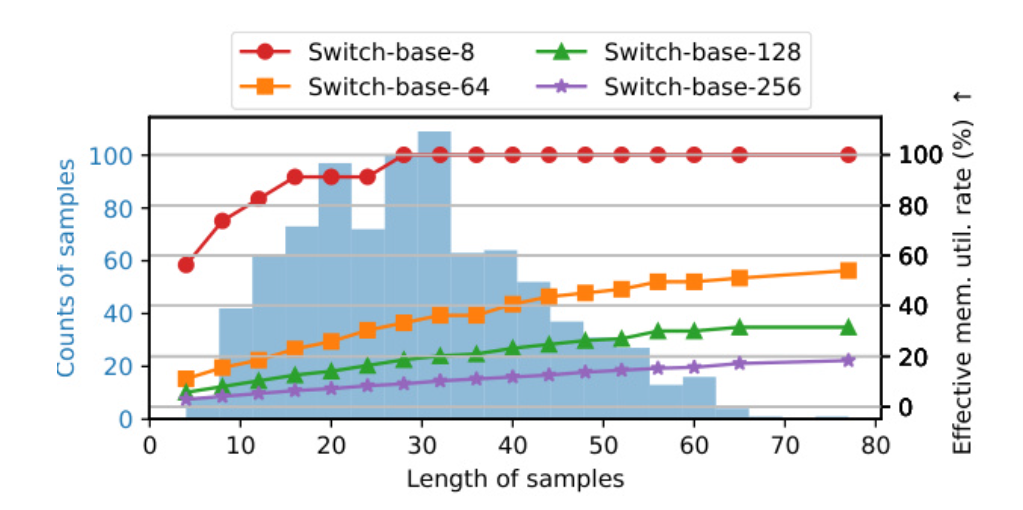
由下图看出大模型(switch-base-256)最低的时候有效GPU-mem利用率只有百分之5
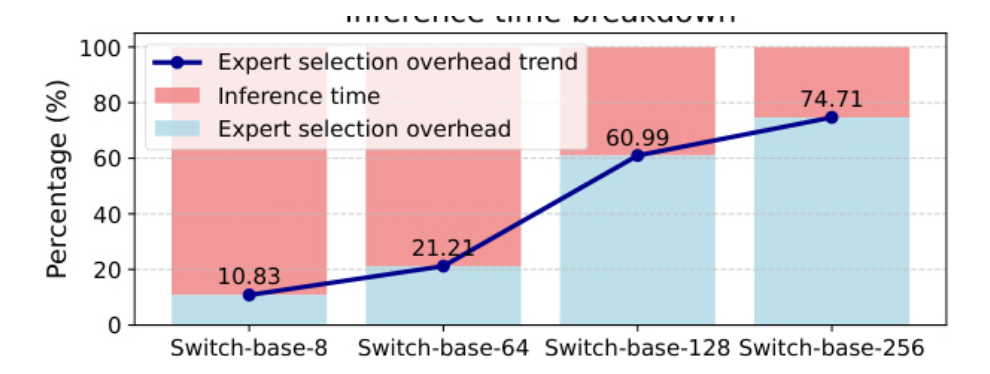
选择专家的开销非常大,并且随着模型规模的扩大选择专家的开销也在扩大,不过为什么会这么大?
sentence level的专家激活任然具有稀疏性
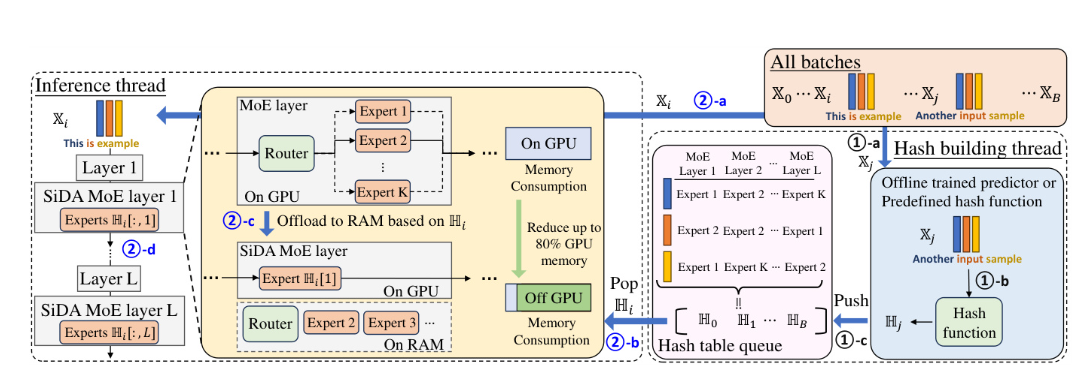
SIDA
由interfence thread和hash build thread(预测句子需要卸载的expert)组成,并行进行,并且预测比推理要快,所以不会带来延迟。
LSTM with sparse attention
这一节在证明对于每个token的专家激活存在稀疏的交叉依赖关系。由于自注意力机制和position embedding的存在,每个token的专家的激活不仅与当前token有关系,而且与其他token以及其他token的位置有关系。但是作者证明了每个token的专家激活只与少数的其他token有关系。
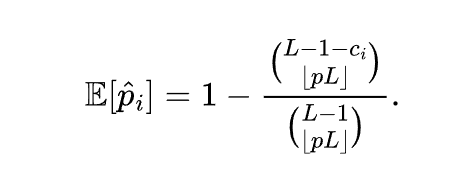
上面这个公式表示的是,从sequence选择出来的一部分token,不包含关键token(与i个token存在依赖的token)的概率。其中\(C_i\)表示第i个token的关键token的数量。
可以通过经验拟合出这个概率:
- 对于token之间的依赖关系:随机选择一部分token当作p,然后改变token,如果专家激活改变则说明p中 含有关键token。p选择越大,概率也就越大
- 对于位置之间的依赖关系:同理,只不过把改变token变成交换token的位置。
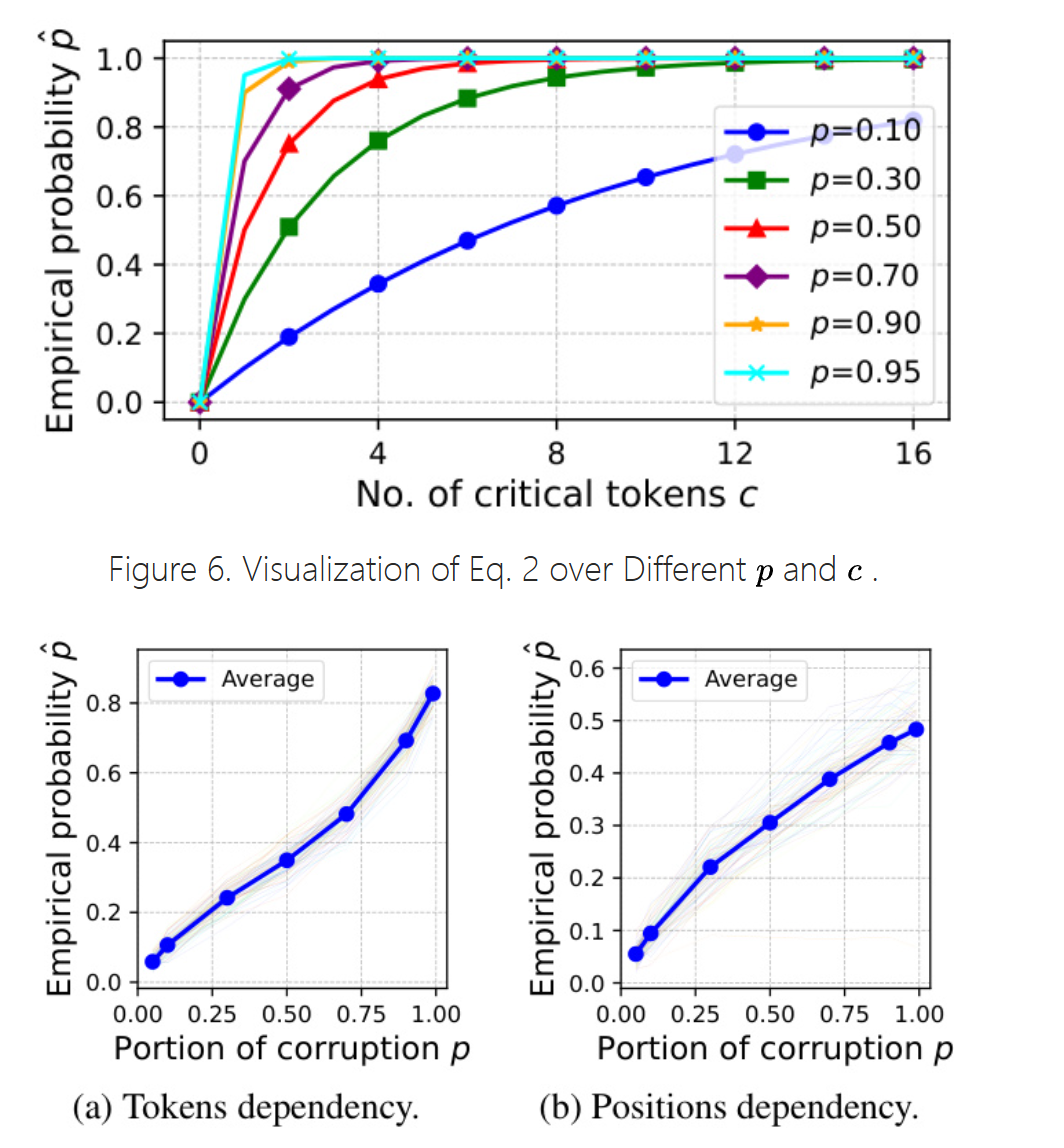
由上图看出,只有c在1-4之间的时候才比较符合概率随p的增长。这证明了稀疏性。
Design of the hash function
不是很清楚细节
两层LSTM,再加一层全连接用来压缩维度,再加一个注意力层,之后用SparseMax激活,SparseMax能为多个位置分配0概率(区别于Softmax)
Decoder-Only or Encoder-Decoder?
introduction
下图展示了decoder-only与encoder-decoder架构的区别
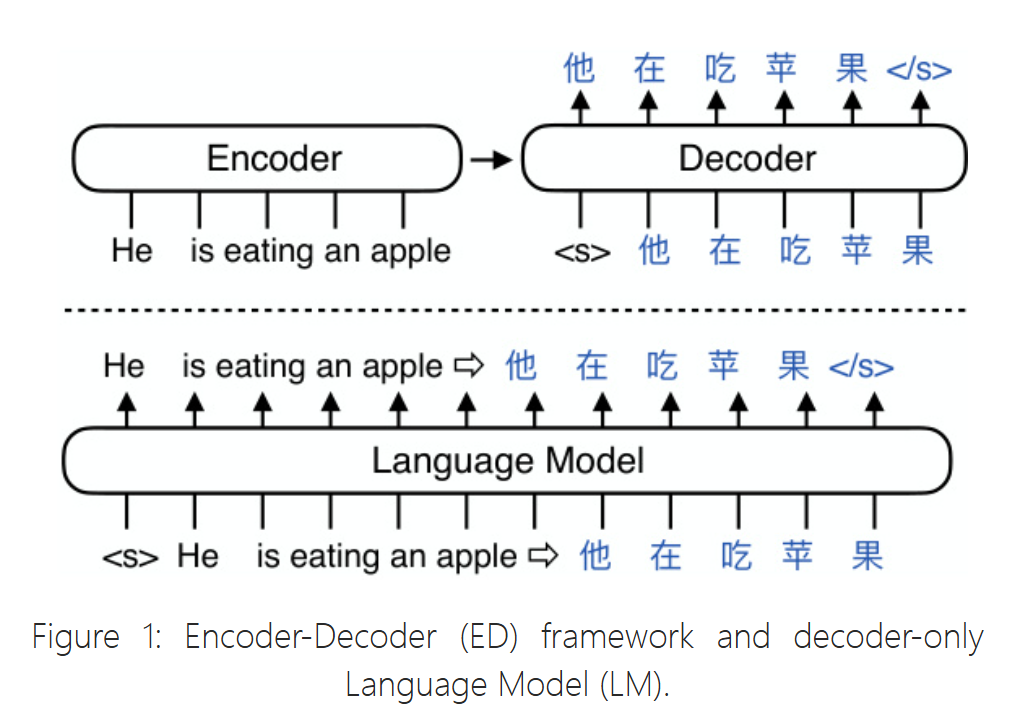
decoder-only Language Model (LM): GPT2 ( Radford et al., 2019), GPT3 ( Brown et al., 2020), InstructGPT/ChatGPT ( Ouyang et al., 2022), Palm ( Chowdhery et al., 2022), OPT ( Zhang et al., 2022), Bloom ( Scao et al., 2022), Galactica ( Taylor et al., 2022), Llama ( Touvron et al., 2023))
decoder-only有许多优势:
- 模型大小显著下降
- 可以预训练未标记的文本数据(?)
- 参数共享,layer-wise coordination(?)
cachegen
这篇论文主要是说通过压缩KV cache,从而减少长文本的prefill阶段的网络延迟。
其中有这样一个insight:Token-wise locality
- 是什么:在同一层,相邻的符元具有更相似的 K/V 张量值,而相距较远的符元则具有更不相同的 K/V 张量值。
- 验证:从下图可以看出来每一对连续token的同一层的KV
tensor的差值(delta)是更集中在0部分。说明连续token的K/V值相近。
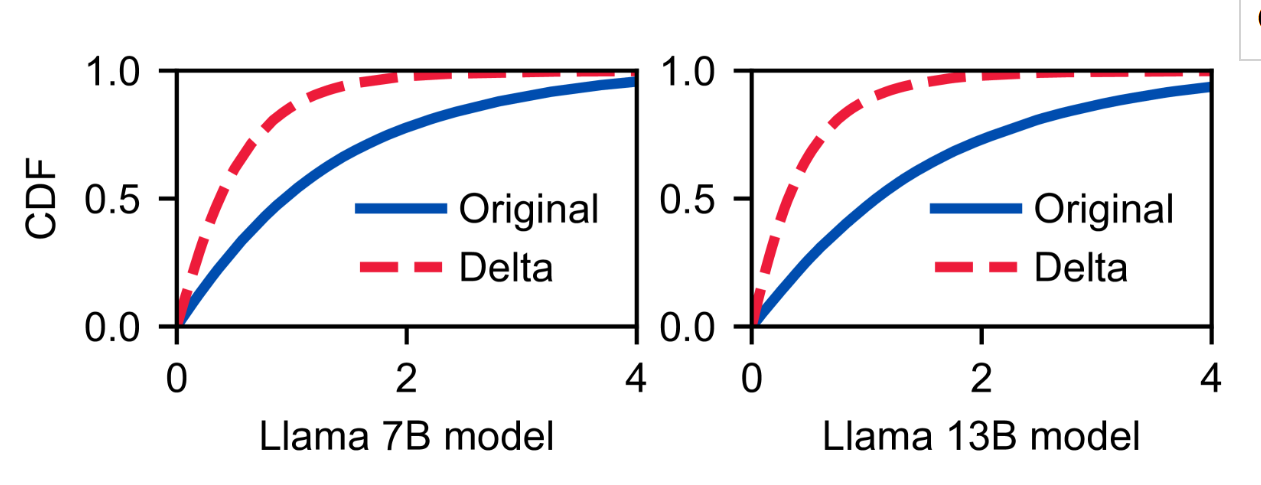
- 解释:作者的解释是说Transformer的子注意力机制使得每一个token的KV tensor基于先前token的KV tensor(感觉缺乏说服力,self-attention没有体现出连续性)
- 作者使用这个现象进行编码的压缩。
Hobbit
introduction
现有的expert-offloading存在的一些问题:
- 不够灵活和过于激进:
- edgemoe的专家卸载根据特定的数据集分析来确定最佳位宽,这会导致在不同环境中的灵活性不足,并可能影响准确性。
- AdapMoE 在发生cache miss的时候直接跳过专家,会导致准确性下降
- prefetch带来的收益有限:expert-loading的成本远大于专家计算的成本
- expert cache的管理不够有效:LFU,LRU虽然高于随机替换策略,但是未能考虑不同模型的独特特征。
motivation
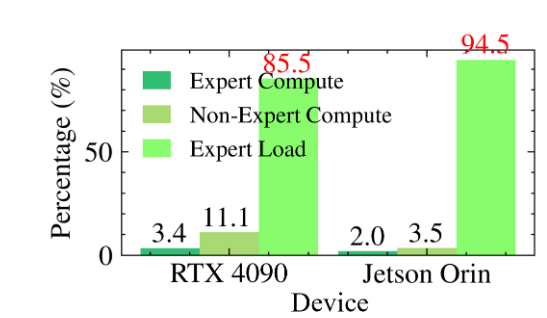
Expert loading dominates inference cost:专家加载的延迟占了推理过程中的大部分延迟,如下图。
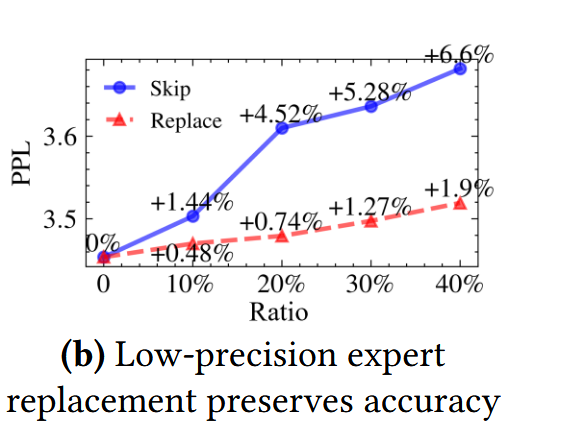
Mixed precision expert preserves model accuracy.:采用动态门控的expert skip方式会导致模型性能的明显下降,但是对一些不太重要的expert进行低精度替换,模型的性能下降很少,但是可以大大加快推理速度。例如,用 int4 版本替换 float16 专家可以在加载过程中实现高达 4 倍的速度提升。
HOBBIT System
Token-level Dynamic Expert Loading:
可以用|G(x)E(x)|来表示专家的重要性,但是在未load专家的时候不能得到E(X),于是用|G(x)|代替。作者做实验验证了两者具有很强的相关性。
Expert loader design.:
作者用下面这个公式计算得分,得分越高则重要性越低:
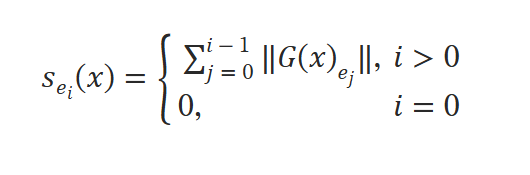
作者设置了两个阈值T1,T2,若得分小于T1,则取高精度expert,若得分小于T2,大于T1则取低精度expert,否则跳过。
Layer-level Adaptive Expert Prefetching
Similarity between layers:
由于LLM中的残差结构,连续层之间具有很强的相似性。作者做实验验证了层之间的余弦相似度。因此可以用当前层的激活来预测后续层的输入,实验验证发现top-1expert的预测精度很高,对于下一层的准确度为96%。
将所有门控的权重堆叠在一起实现
prefetch不同精度的expert,这可以减少由cache miss带来的损失,如下图:
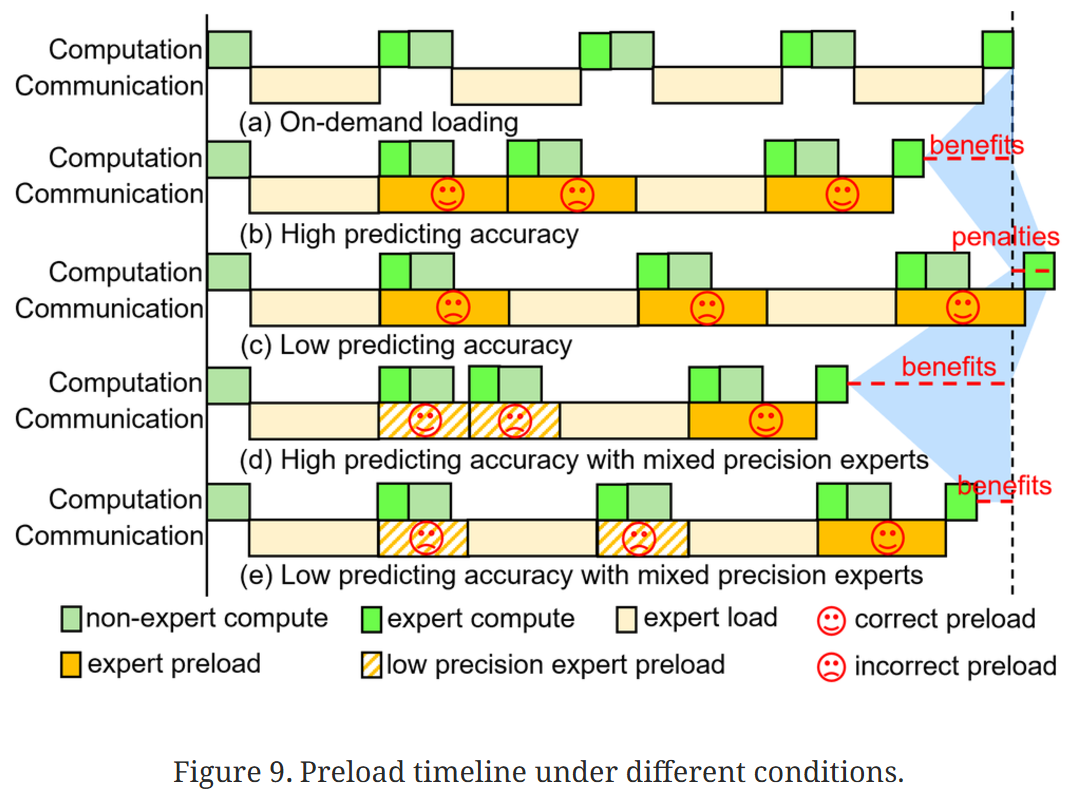
Sequence-level Multidimensional Expert Caching
LRU:在mixtral8x7b中,当前token的top-1专家在下一个token的处理过程中也被用到的概率非常高。
LFU:不同专家对不同序列的偏好有所不同
FLD:相近层的专家更有可能被使用
由于作者使用的是混合精度的expert,因此不能用单纯的缓存命中率来评估替换策略,因为不同精度的专家会产生不同的惩罚。如果专家未命中,则加载其高精度版本的成本为 C,而低精度版本的成本为 Bl/Bh*C,其中 Bl 和 Bh 分别是低精度版本和高精度版本的位宽。
作者还提出了LHU:与LFU相似,但是LHU考虑的是高精度expert。一个expert被命中的次数多,但是可能都是命中低精度expert。
利用上述四种策略的优势,我们通过为每种策略分配权重并将其相加来确定每个专家的最终优先级。 如下:
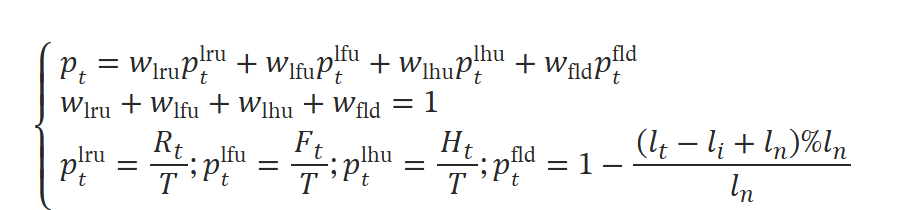
四个权重是用户设置的超参数,通过最小化校准数据集上的混合精度专家缓存未命中惩罚来确定合适的数值。
缓存管理器为高精度专家和低精度专家维护单独的缓存,如下图所示:
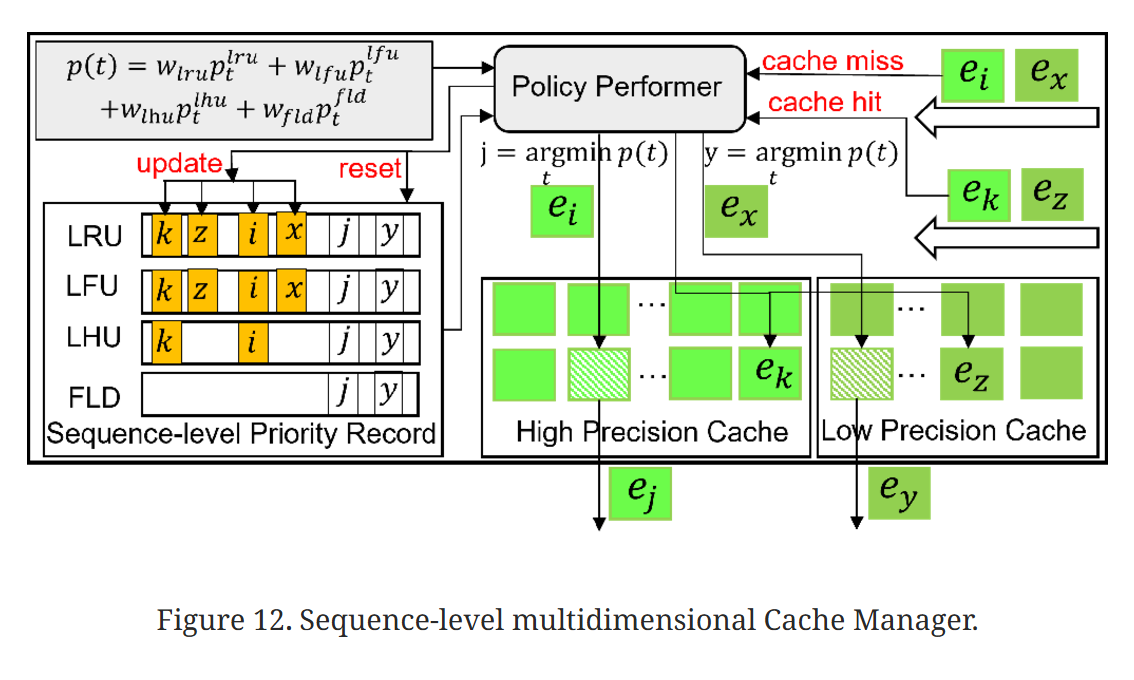
System Implementation
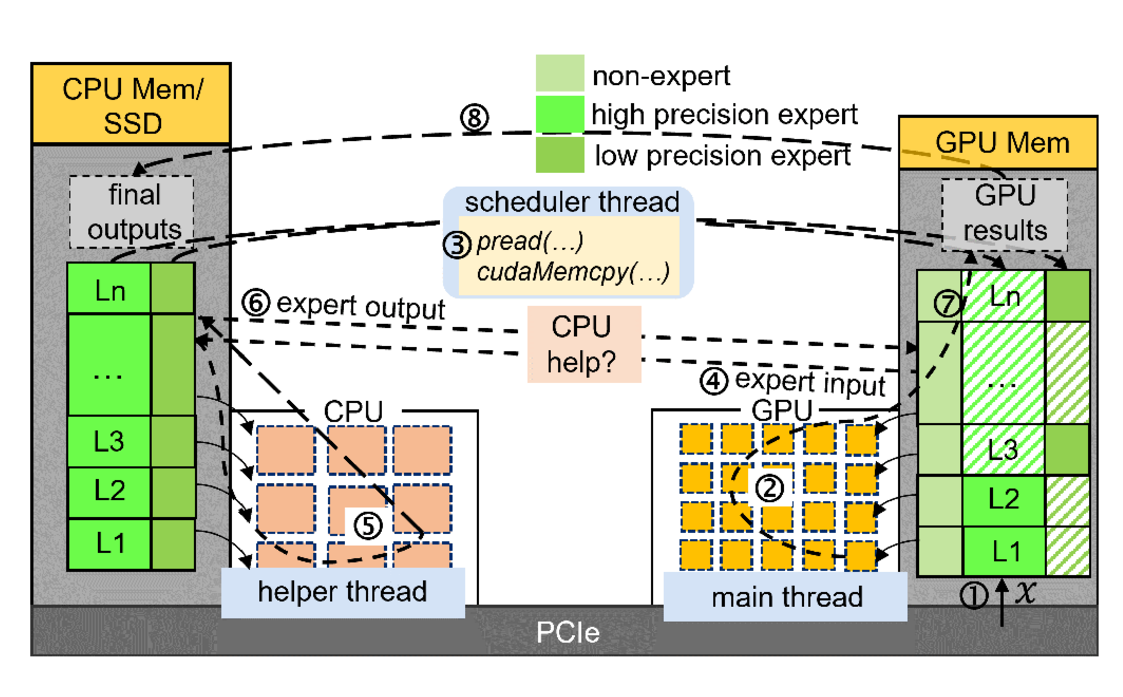
GPU上有部分专家权重和所有的非专家权重,CPU上有所有的专家权重
作者实现了两种实现方式:
以GPU为中心:当专家不在GPU中时,通过scheduler thread去CPU中复制专家权重
CPU-GPU协同:当专家不在GPU时,把input发送到CPU,由CPU计算完成后再发送计算结果回来
如下图:
HEXA-moe
introduction
moe框架与密集模型有一些不同之处:
- Moe的规模更大,同一层中的不同专家需要放到不同的设备上进行分布式计算,即专家并行。
- 许校准每个专家的工作量来使用GeMM
- 每个token可以激活任意一个或者多个专家,因此在进入专家之前和之后都需要一次all-to-all通信。
这会导致一些问题:
- 调度和组合操作会导致token的padding和丢弃,导致冗余计算和性能损失
- 专家并行依赖all-to-all通信,需要同步,产生大量延迟
- 专家并行主要部署在同构设备上,成本较高。然而由于moe层的动态负载,要实现异构设备的部署也很难。