MoE混合专家模型
什么是混合专家模型?
混合专家模型是一种基于Transformer架构的模型,所以需要先了解Transformer架构
下图详细的展示了transformer架构 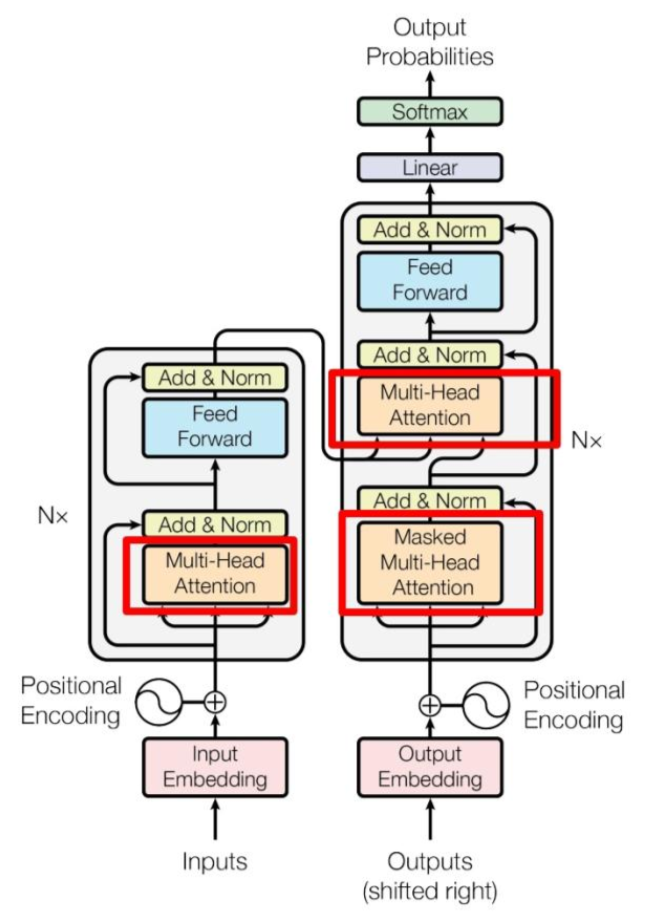
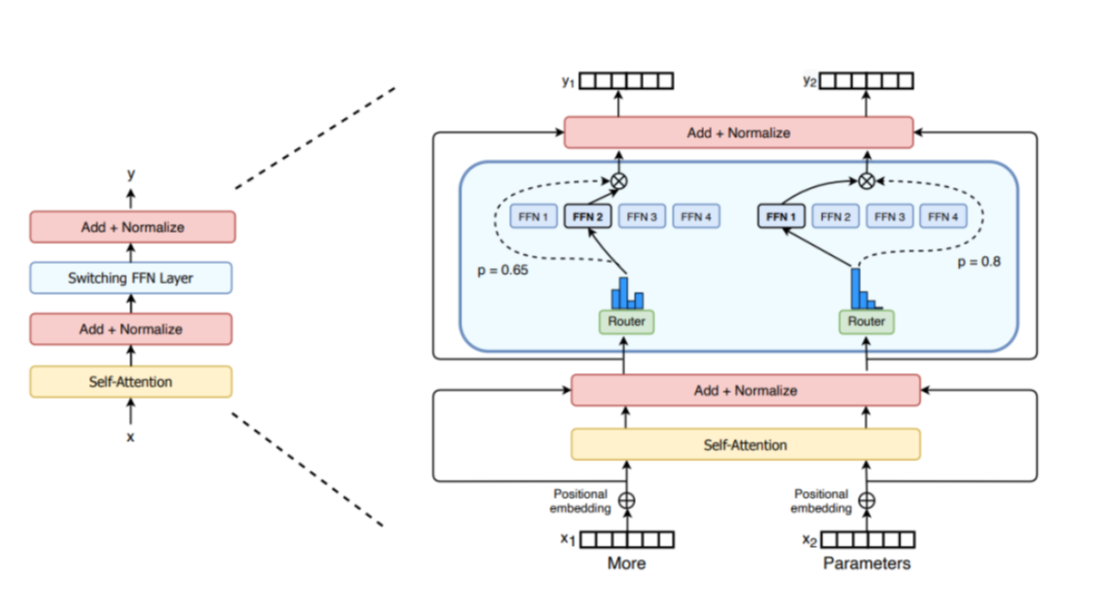
混合专家模型主要由两个关键部分组成:
* 稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN)
层。MoE 层包含若干“专家”(例如 8
个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络
(FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE
层本身,从而形成层级式的 MoE 结构。 * 门控网络或路由:
这个部分用于决定哪些令牌 (token)
被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是
MoE
使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
 # TUTEL: ADAPTIVE
MIXTURE-OF-EXPERTS AT SCALE ## abstract Based on adaptive
parallelism/pipelining optimization-> Flexible All-to-All,
two-dimensional hierarchical (2DH) All-to-All, fast
encode/decode(contuibution)
# TUTEL: ADAPTIVE
MIXTURE-OF-EXPERTS AT SCALE ## abstract Based on adaptive
parallelism/pipelining optimization-> Flexible All-to-All,
two-dimensional hierarchical (2DH) All-to-All, fast
encode/decode(contuibution)
training and inference ## introduction dynamic nature of MoE:This
implies that the workload of experts is fundamentally uncertain ###
three methods * adjust paralleism at runtime:large redistribution
overhead and GPU memeory
* load balance loss:harm model arrcuacy * Tutel: dynamically switches
the parallelism strategy at every iteration without any extra overhead
of switching. ## BACKGROUND & MOTIVATION ### Sparsely-gated
Mixture-of-Experts (MoE) 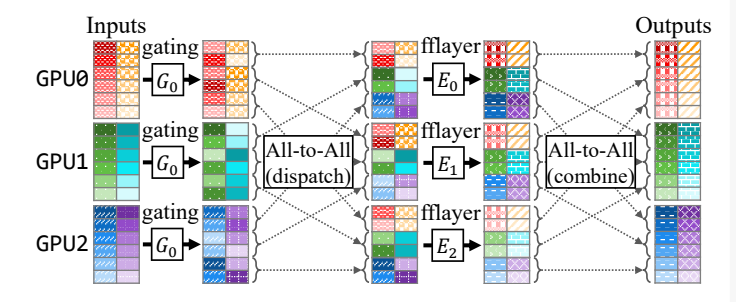 ### Dynamic Workload of
MoE f? set f to a static upper bound of capacity factor? ### Static
Parallelism the best parallelism method depends on the workload and
switching between different parallelism methods during runtime would
incur a substantial overhead.
### Dynamic Workload of
MoE f? set f to a static upper bound of capacity factor? ### Static
Parallelism the best parallelism method depends on the workload and
switching between different parallelism methods during runtime would
incur a substantial overhead.
 ### Static Pipelining
depending on different MoE settings and scales,the corresponding optimal
pipelining strategy consists of various All-to-All algorithms (Linear or
2DH3) and pipelining degrees. ## ADAPTIVE MOE WITH TUTEL ### Adaptive
Parallelism Switching DP
### Static Pipelining
depending on different MoE settings and scales,the corresponding optimal
pipelining strategy consists of various All-to-All algorithms (Linear or
2DH3) and pipelining degrees. ## ADAPTIVE MOE WITH TUTEL ### Adaptive
Parallelism Switching DP
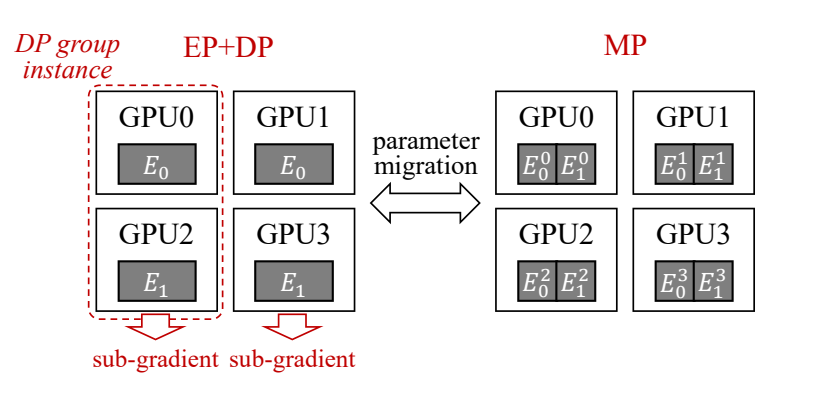
EP+DP+MP ### DP a single all-reduce naturally consists of a
reduce-scatter and an all-gather. ### DP+EP+MP  ## IMPLEMENTATION ###
Features * Dynamic Top-ANY MoE Gating * Dynamic Capacity Factor
## IMPLEMENTATION ###
Features * Dynamic Top-ANY MoE Gating * Dynamic Capacity Factor
自我理解和总结:通过单一的适用于所有可能的最优策略数据布局,使得切换并行策略时不需要对数据进行迁移。通过数据划分,实现all2all通信和专家计算的重叠以此实现流水线。将各种参数的性能存在字典里,训练时查字典实现自适应性。
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
Abstract
DeepSpeed-MoE:novel MoE architecture designs and model compression
techniques,a highly optimized inference system.
## Introduction set of challenges: * Limited Scope The scope of MoE
based models in the NLP area is primarily limited to encoder-decoder
models and sequence-to-sequence tasks * Massive Memory Requirements:
need significantly more number of parameters * Limited Inference
Performance:On one hand, the larger parameter size requires more GPUs to
fit. On the other hand, as inference is often memory bandwidth bound
three corresponding solutions: * We expand the scope of MoE based
models * We improve parameter efficiency of MoE based models:PR-MoE
MoS
* We develop DeepSpeed-MoE inference system
PR-MoE and MoS: Reducing the Model Size and Improving Parameter Efficiency
- 现象1:Deeper layers benefit more from large number of experts.
- 现象2:We find out that the generalization performance of these two
(aka Top2-MoE and Residual-MoE) is on-par with each other.
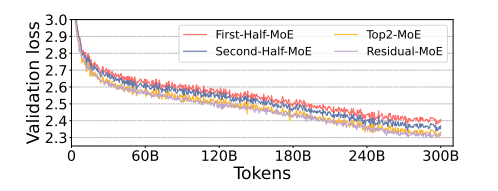
->PR-MoE ### MoS 什么是知识蒸馏? ## DeepSpeed-MoE Inference the MoE inference performance depends on two main factors: the overall model size and the overall achievable memory bandwidth. ### Design of DeepSpeed-MoE Inference System #### Expert, Tensor and Data parallelism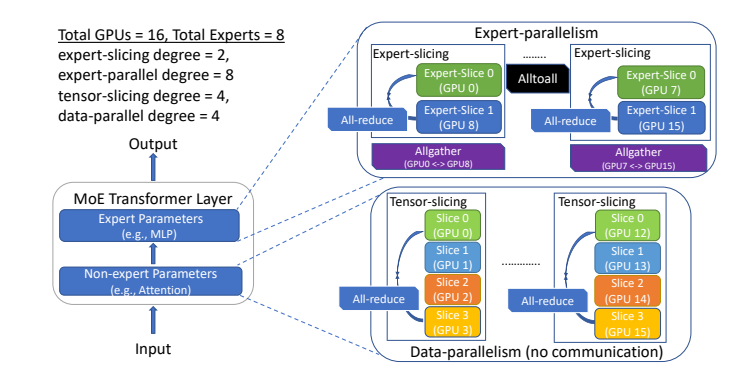 #### Hierarchical
All-to-all
#### Hierarchical
All-to-all 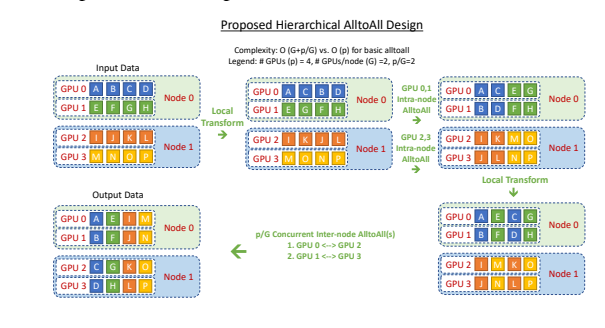 ####
Parallelism Coordinated Communication
####
Parallelism Coordinated Communication 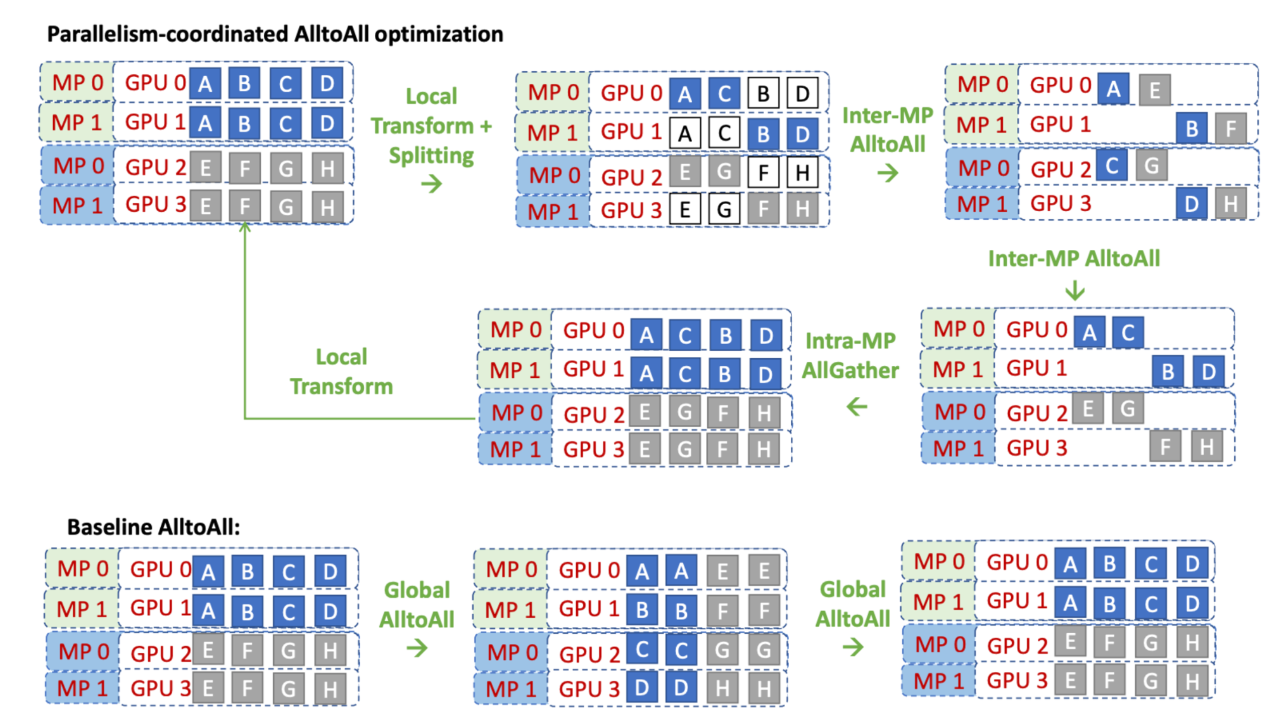 #### Kernel Optimizations
??
#### Kernel Optimizations
??
理解和总结:模型的优化有PR-MoE和MoS,推理的优化:分布式切分,通信优化,kernel优化。 # GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding ## Abstract GShard enabled us to scale up multilingual neural machine translation Transformer model with Sparsely-Gated Mixture-of-Experts beyond 600 billion parameters using automatic sharding ## Introduction While the final model quality was found to have a power-law relationship with the amount of data, compute and model size [18, 3], the significant quality gains brought by larger models also come with various practical challenges. ### Practical Challenges for Scaling * Architecture-specific model parallelism support: users typically need to invest a lot of engineering work, for example, migrating the model code to special frameworks。 * Super-linear scaling of computation cost vs model size * Infrastructure scalability for giant model representation:Such increase in the graph size would result in an infeasible amount of graph building and compilation time for massive-scale models.
Design Principles for Efficient Training at Scale
- Sub-linear Scaling:Scaling capacity of RNN-based machine translation and language models by adding Position-wise Sparsely Gated Mixture-of-Experts (MoE) layers [ 16] allowed to achieve state-of-the-art results with sublinear computation cost.
- Second, the model description should be separated from the partitioning implementation and optimization.
- he system infrastructure, including the computation representation
and compilation, must scale with thousands of devices for parallel
execution. ## Model
### Sparse scaling of the Transformer architecture we sparsely scale Transformer withconditional computation by replacing every other feed-forward layer with a Position-wise Mixture of Experts (MoE) layer [ 16] with a variant of top-2 gating in both the encoder and the decoder ### Position-wise Mixture-of-Experts Layer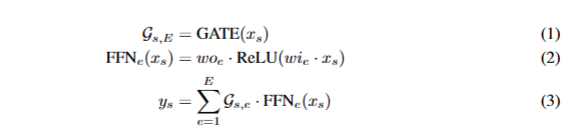 xs is the input token to
the MoE layer, wi and wo being the input and output projection matrices
for the feed-forward layer (an expert).
xs is the input token to
the MoE layer, wi and wo being the input and output projection matrices
for the feed-forward layer (an expert).
gating function must satisfy two goals:
- Balanced load: better design of the gating function would distribute processing burden more evenly across all experts.
- Efficiency at scale:we need an efficient parallel implementation of the gating function to leverage many devices.
echanisms in the gating function GATE(·) to meet the above
requirements (details illustrated in Algorithm 1): * Expert capacity: To
ensure the load is balanced, we enforce that the number of tokens
processed by one expert is below some uniform threshold * Local group
dispatching GATE(·):in this way, we can ensure that expert capacity is
still enforced and the overall load is balanced. * Auxiliary
loss:如果把token都分给一个人,loss就很高,分的越均匀(最好是彻底均分),loss越小
* Random routing: if the weight for the 2nd expert is very small, we can
simply ignore the 2nd expert to conserve the overall expert
capacity.
具体过程: 
总结和理解:这篇论文把MoE结构放入Transformer模型中,通过限制专家容量,每个token分配的专家数量和一个额外的loss实现门控函数的负载均衡。